Writing PySpark logs in Apache Spark and Databricks
The closer your data product is getting to the production, the bigger is the importance of properly collecting and analysing logs. Logs help both during debugging in-depth issues and analysing the behaviour of your application.
For general Python applications the classical choice would be to use the built-in logging library which has all the necessary components and provides very convenient interfaces for both configuring and working with the logs.
For PySpark applications, the logging configuration is a little bit more intricate, but still very controllable — it’s just done in a slightly different way, contrary to the classical Python logging.
In this blogpost I would like to describe approach to effectively create and manage log setup in PySpark applications, both in local environment and on the Databricks clusters.
If you are looking for the source code, please find it here.
A little bit of theory
Apache Spark uses log4j package under the hood. Therefore, to properly pass logging messages and unify them across multiple APIs, we’ll need to initialize the logger in a slightly different way, compared to the usual logging package for Python applications.
In a classical Python environment the logger instance is initialized in the following way:
import logging logger = logging.getLogger("logger_name")
However for PySpark applications, we’ll need to use the py4j bridge to properly initialize the logger:
In this code we do the following:
- Get the LogManager object via py4j bridge
- Obtain the class name with it’s module name and optional
custom_prefix - Return the initialized logger object
However, simply creating the logger object is not enough, since we also need to provide log4j.properties file. In this file we’ll define the formatting of the logging strings and different levels for packages from which we’re going to collect the logs.
Apache Spark setup
While running PySpark applications locally, you most probably are going to install the pyspark package via pip:
pip install pysparkAnd in your application code you most probably are going to initialize the SparkSession object via the following block of code:
class SomeApplication:
def __init__(self):
self.spark = SparkSession.builder.getOrCreate()It’s pretty simple to add to this block the logger definition, based on the above-mentioned snippet:
# located in some_package.some_moduleclass SampleApp(LoggerProvider):
def __init__(self):
self.spark = SparkSession.builder.getOrCreate()
self.logger = self.get_logger(self.spark)
By inheriting the LoggerProvider class, we simplify the process of recognising the SampleApp module name, so in our logs it will be represented as:
some_package.some_module.SampleApp <here goes the message>Now to use this logger object we can simply add the following:
class SampleApp(LoggerProvider):
def __init__(self):
self.spark = SparkSession.builder.getOrCreate()
self.logger = self.get_logger(self.spark)
def launch(self):
self.logger.debug("some debugging message")
self.logger.info("some info message")
self.logger.warn("some warning message")
self.logger.error("some error message")
self.logger.fatal("some fatal message")Please note the method names for the self.logger object — they’re not the same as a classical logging.Logger API. Since this logger object is based on log4j, it shall follow the log4j methods (e.g. not warning but warn and not critical but fatal).
If we now launch this application in the local environment, we’ll see that not all messages are actually getting to the output. Also, we might would like to add a bit more detailed formatting to the logs itself:
22/06/11 18:39:41 WARN SampleLoggingJob: some warning message
22/06/11 18:39:41 ERROR SampleLoggingJob: some error message
22/06/11 18:39:41 FATAL SampleLoggingJob: some fatal messageNow it’s time to introduce new file — log4j.properties . You can find a reference file here. You can easily provide a customized version of this file by using the SPARK_CONF_DIR environment variable as described here.
At first, let’s start from something basic:
If we’ll launch this with our code, we suddenly won’t see any proper logs in the output, but the formatting will be applied properly:
[spark][2022-06-13 12:29:26][WARN][org.apache.hadoop.util.NativeCodeLoader][Unable to load native-hadoop library for your platform... using builtin-java classes where applicable]
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
[spark][2022-06-13 12:29:27][WARN][pyspark_logging_examples.workloads.sample_logging_job.SampleLoggingJob][some warning message]
[spark][2022-06-13 12:29:27][ERROR][pyspark_logging_examples.workloads.sample_logging_job.SampleLoggingJob][some error message]
[spark][2022-06-13 12:29:27][FATAL][pyspark_logging_examples.workloads.sample_logging_job.SampleLoggingJob][some fatal message]We can also notice this strange line in the log output:
Setting default log level to "WARN".This is where thing get a little bit counterintuitive — although we might expect that the default log level for PySpark applications is taken from log4j.rootCategory=DEBUG, console , it’s actually not exactly true. We’ll need to add another configuration line when we’re running the PySpark application locally:
log4j.logger.org.apache.spark.api.python.PythonGatewayServer=DEBUGWith this line and some log formatting we’ll have the following file:
And if we launch our application now we’ll get a really rich log output (maybe even too verbose):
spark][2022-06-13 12:33:55][DEBUG][org.sparkproject.jetty.util.component.AbstractLifeCycle][starting ServletHandler@694d6976{STOPPED}]
[spark][2022-06-13 12:33:55][DEBUG][org.sparkproject.jetty.servlet.ServletHandler][Path=/[EMBEDDED:null] mapped to servlet=org.apache.spark.ui.JettyUtils$$anon$1-42fde1ed[EMBEDDED:null]]
[spark][2022-06-13 12:33:55][DEBUG][org.sparkproject.jetty.http.pathmap.PathMappings][Added MappedResource[pathSpec=ServletPathSpec@4e{/},resource=org.apache.spark.ui.JettyUtils$$anon$1-42fde1ed==org.apache.spark.ui.JettyUtils$$anon$1@bace2775{jsp=null,order=-1,inst=false,async=true,src=EMBEDDED:null,STOPPED}] to PathMappings[size=1]]
[spark][2022-06-13 12:33:55][DEBUG][org.sparkproject.jetty.servlet.ServletHandler][filterNameMap={org.apache.spark.ui.HttpSecurityFilter-566be2b0=org.apache.spark.ui.HttpSecurityFilter-566be2b0==org.apache.spark.ui.HttpSecurityFilter@566be2b0{inst=false,async=true,src=EMBEDDED:null}}]
[spark][2022-06-13 12:33:55][DEBUG][org.sparkproject.jetty.servlet.ServletHandler][pathFilters=[[/*]/[]/[INCLUDE, REQUEST, FORWARD, ERROR, ASYNC]=>org.apache.spark.ui.HttpSecurityFilter-566be2b0]]
[spark][2022-06-13 12:33:55][DEBUG][org.sparkproject.jetty.servlet.ServletHandler][servletFilterMap={}]
[spark][2022-06-13 12:33:55][DEBUG][org.sparkproject.jetty.servlet.ServletHandler][servletPathMap=PathMappings[size=1]]
[spark][2022-06-13 12:33:55][DEBUG][org.sparkproject.jetty.servlet.ServletHandler][servletNameMap={org.apache.spark.ui.JettyUtils$$anon$1-42fde1ed=org.apache.spark.ui.JettyUtils$$anon$1-42fde1ed==org.apache.spark.ui.JettyUtils$$anon$1@bace2775{jsp=null,order=-1,inst=false,async=true,src=EMBEDDED:null,STOPPED}}]
[spark][2022-06-13 12:33:55][DEBUG][org.sparkproject.jetty.server.handler.AbstractHandler][starting ServletHandler@694d6976{STARTING}]
[spark][2022-06-13 12:33:55][DEBUG][org.sparkproject.jetty.util.component.AbstractLifeCycle][STARTED @2251ms ServletHandler@694d6976{STARTED}]Now it’s time to actually configure it properly, so we see only relevant messages from our application and suppress too much detailed logging information. In this example we follow the log4j.properties.template with some minor adjustments:
The logs look now way less verbose, but it seems to me that I’ve lost the debugging details from my application:
[spark][2022-06-13 12:39:06][INFO][pyspark_logging_examples.workloads.sample_logging_job.SampleLoggingJob][some info message]
[spark][2022-06-13 12:39:06][WARN][pyspark_logging_examples.workloads.sample_logging_job.SampleLoggingJob][some warning message]
[spark][2022-06-13 12:39:06][ERROR][pyspark_logging_examples.workloads.sample_logging_job.SampleLoggingJob][some error message]
[spark][2022-06-13 12:39:06][FATAL][pyspark_logging_examples.workloads.sample_logging_job.SampleLoggingJob][some fatal message]This output is missing the debugging commands I’ve had in my application — and it makes sense since I’ve set our root and GatewayServer configuration to INFO level. Here the log4j configuration flexibility comes in handy. Since I know that the name of my package is pyspark_logging_examples — I can adjust my logging output based on it’s name by simply adding one line:
# Custom line for my Python packagelog4j.logger.pyspark_logging_examples=DEBUGNow we’re talking — all logs are properly printed:
[spark][2022-06-13 12:45:20][DEBUG][pyspark_logging_examples.workloads.sample_logging_job.SampleLoggingJob][some debugging message]
[spark][2022-06-13 12:45:20][INFO][pyspark_logging_examples.workloads.sample_logging_job.SampleLoggingJob][some info message]
[spark][2022-06-13 12:45:20][WARN][pyspark_logging_examples.workloads.sample_logging_job.SampleLoggingJob][some warning message]
[spark][2022-06-13 12:45:20][ERROR][pyspark_logging_examples.workloads.sample_logging_job.SampleLoggingJob][some error message]
[spark][2022-06-13 12:45:20][FATAL][pyspark_logging_examples.workloads.sample_logging_job.SampleLoggingJob][some fatal message]In the same manner you can mute (or add) more detailed logs per different components of Apache Spark — just notice the ones that are too verbose and point them to a higher level, e.g. if I think that the DAG scheduler logs are too verbose on the INFO level, I can simply cap them to WARN level:
log4j.logger.org.apache.spark.scheduler.DAGScheduler=WARNSummarizing on this path, here are some important things to consider when driving PySpark application logs in the OSS Apache Spark environment:
- Use the Spark-based logger and not the logging-based one
- Provide your logging configurations in
log4j.propertiesfile and place it in theSPARK_CONF_DIRpath - Don’t forget to keep in sync the
rootCategoryandPythonGatewayServerlogging properties - You can easily customize your logging levels per different loggers (which could be your application or specific Apache Spark class or package)
Managing logging configurations in the Databricks environment
On the Databricks platform, we’ll reuse the above mentioned class called LoggerProvider to write the logs:
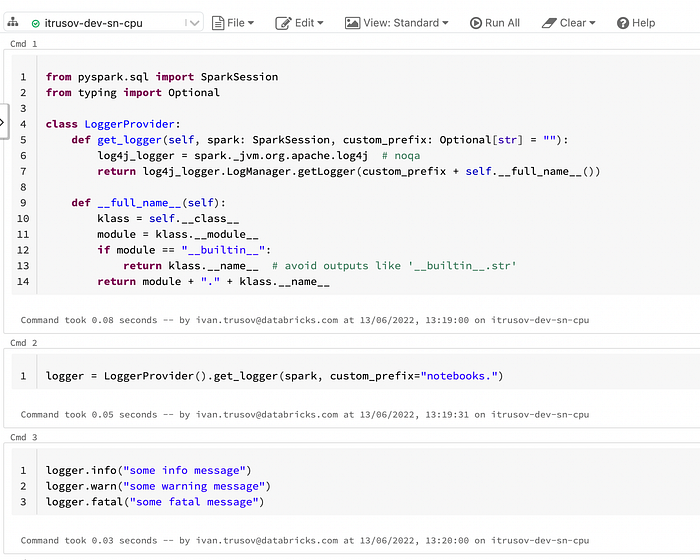
After running this code, in the Driver Logs tab, in the log4j output we’ll see the following lines:
22/06/13 11:20:00 INFO LoggerProvider: some info message
22/06/13 11:20:00 WARN LoggerProvider: some warning message
22/06/13 11:20:00 FATAL LoggerProvider: some fatal messageHowever we also would like to slightly customize the logging output (add more formatting and add the fully qualified class names to it). We can easily do this by using the cluster node initialization script as described here.
We’ll need to change the layout of the publicFile appender to the following:
log4j.appender.publicFile.layout.ConversionPattern=[spark][%p][%d{yy/MM/dd HH:mm:ss}][%c][%m]%nAnd now in the log4j section we see pretty clean log output:
[spark][INFO][22/06/13 11:56:01][notebooks.__main__.LoggerProvider][some info message]
[spark][WARN][22/06/13 11:56:01][notebooks.__main__.LoggerProvider][some warning message]
[spark][FATAL][22/06/13 11:56:01][notebooks.__main__.LoggerProvider][some fatal message]however we might have a lot of different notebooks using the same cluster at a time, so it would be great to properly prepend the path to uniquely distinguish different logs:
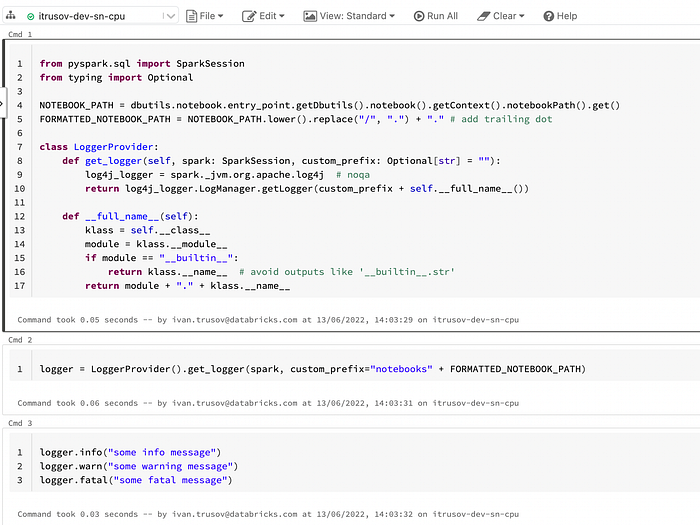
And now our logs provide full visibility on the path on the source notebook:
[spark][INFO][22/06/13 12:03:32][notebooks.some.path.sample-logs-collection.__main__.LoggerProvider][some info message]
[spark][WARN][22/06/13 12:03:32][notebooks.some.path.sample-logs-collection.__main__.LoggerProvider][some warning message]
[spark][FATAL][22/06/13 12:03:32][notebooks.some.path.sample-logs-collection.__main__.LoggerProvider][some fatal message]By further customizing the log4j.properties you can suppress specific components and classes from the logs (or enable a more in-depth debugging for specific parts).
You can find all the above mentioned code pieces and more profound example in this repository.
In this post I’ve tried to cover different options for configuring log4j and using it as a main logging engine for a PySpark application both in OSS Apache Spark and Databricks context. The one topic which remained not properly covered is the setup, configuration and collection of the logs on the worker nodes.
