Using OpenAI with Databricks SQL for queries in natural language

Intro
Modern data platforms store and collect an incredible amount of both useful data and metadata. However, even knowing the metadata itself might be not useful for the end-users who don’t have enough experience with classical components of a relation-based data model. One of the challenges is not only the ability to write proper SQL statements to select the relevant information but also understanding of what needs to be joined (and how exactly this shall be done) even to get the simplest insights (e.g. top-5 customers from a given region by the number of orders).
The more well-thought and clean-engineered the data model is the more non-trivial level of knowing SQL and both data layout need the nontechnical end-users to simply understand how to acquire the relevant information.
Can modern GPT-3 based solutions help end-users to overcome the challenge and provide a decent level of translation from natural to SQL language? This is something I wanted to discover first when I’ve seen the OpenAI API and its SQL translate capabilities powered by the Davinci engine.
Looking ahead, I can answer somewhat positive to the question above, and here is the link if you’re eager to see the code and try it out in your environment.
Solution Architecture
To outline the big picture, in this example I’m going to build the following:
- A sample frontend application for entering natural language queries
- A backend which integrates Databricks SQL and OpenAI API and serves the results to the frontend
Details of the implementation are described on the schema below:

As a dataset schema I’ve been using the TPCH dataset sample which is by default accessible by any user of the Databricks platform. I assume that TPCH dataset was widely used by the OpenAI to actually train its SQL translate capability, so I’ll be really interested in how this would work in a more real-life application scenario.
Therefore, I encourage you to actually try the approach with your real data to see how it would work — take a look at the instructions in the linked repository to launch it with your data schema.
One thing I definitely discourage is to look at the frontend application code — since my knowledge of React is relatively bad, and I know that the code part there is far-far away from looking like cherry blossom.
Collecting metadata
First of all we start from the collecting metadata from Databricks SQL.
Since I’m using FastAPI as a backend server, a natural way to collect metadata is to use the Databricks SQL connector for Python to collect the table schemas via DBSQL endpoint connection object:
As you can see there is no much magic around that, for convenience I’ve moved all the methods to a separate class called EndpointManager. You can find the full implementation here.
Working with OpenAI SQL translate capabilities
Secondary, we’ll need to prepare the query in an expected prompt format described in the OpenAI API spec. You can find the relevant code here, in the Translator class. Here is how a prepared prompt based on my TPCH schema looks like:
### Databricks SQL tables, with their properties:
#
# field_demos.core.customer(c_custkey,c_name, ...)
# field_demos.core.lineitem(l_orderkey,l_partkey, ...)
# field_demos.core.nation(n_nationkey,n_name,n_regionkey,n_comment)
# field_demos.core.orders(o_orderkey,o_custkey, ...)
# field_demos.core.part(p_partkey,p_name, ...)
# field_demos.core.partsupp(ps_partkey,ps_suppkey, ...)
# field_demos.core.region(r_regionkey,r_name,r_comment)
# field_demos.core.supplier(s_suppkey,s_name, ...)
#
### show top 5 customers by the number of orders
SELECTAs you could notice, the first line is just the header which doesn’t really contain any metadata information. Following lines contain the full name of the table, plus the list of columns in round brackets. Finally, after the schema user shall provide the query in the natural language that is expected to be translated to a SQL statement which starts from a SELECT section.
After generating the prompt, it’s not really much to do about it — we simply process the received query and then send it to the DBSQL endpoint for execution. Let’s play a little bit with this simple UI and check what results could be achieved by using this fairly simple setup.
Examples
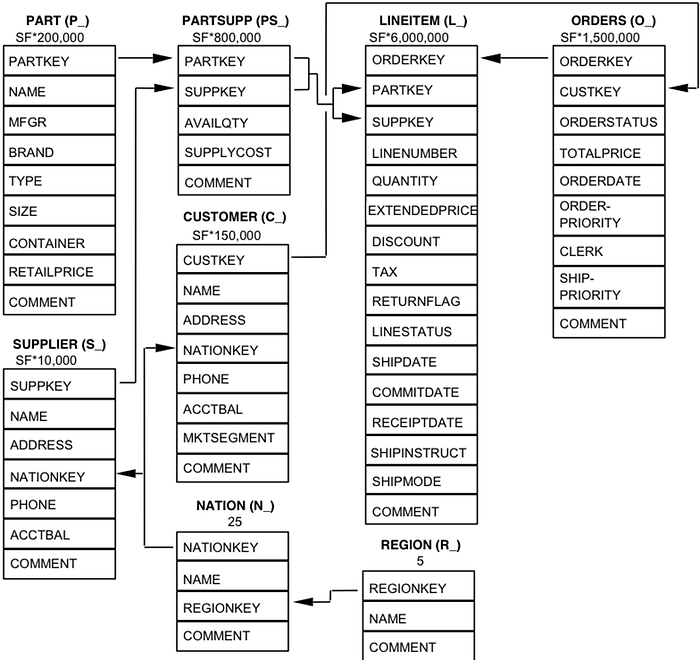
Here is a quick picture of TPCH schema for a reference:
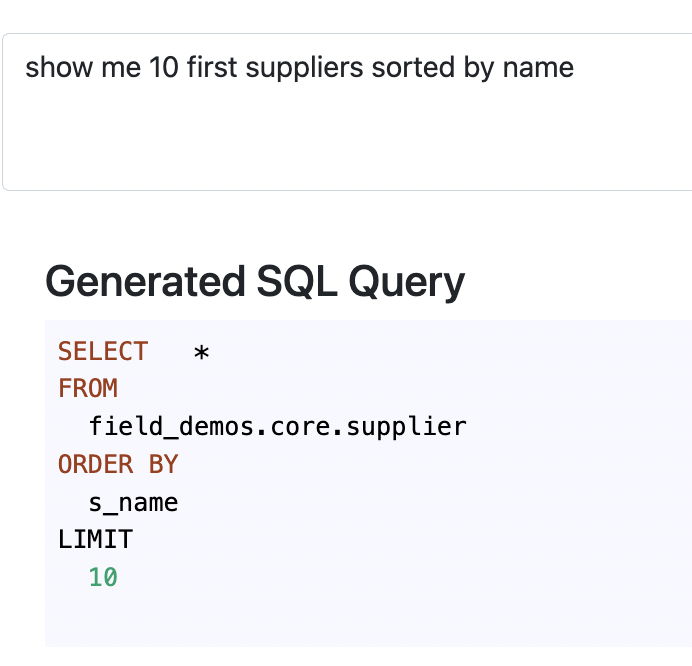
Lets start from something trivial — single-table requests:
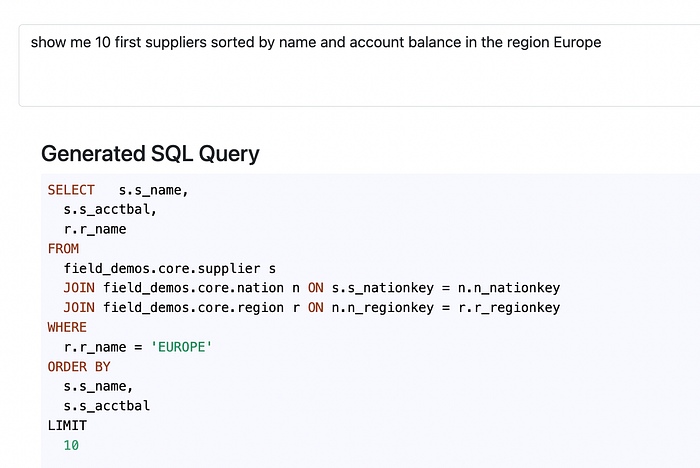
This looks already pretty promising, since OpenAI model has correctly identified the right table, as well as the column relevant to the name. Let’s make the task a little bit more challenging and add another sorting axis:
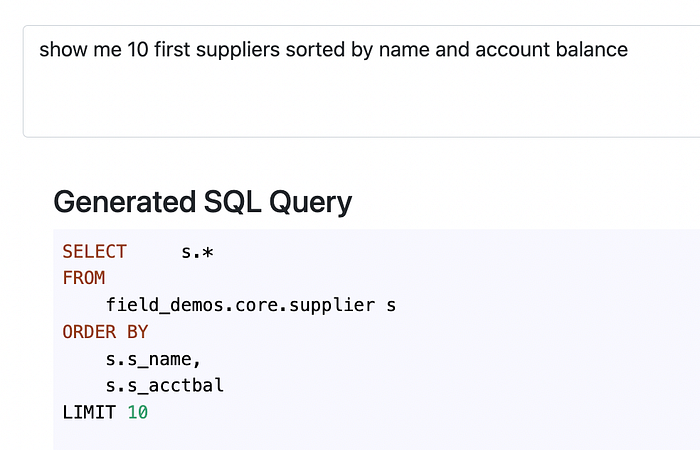
And even this looks good, surprisingly successful first shots.
Let’s add a little bit more complexity to our exercise, by adding other tables into our conditioning:
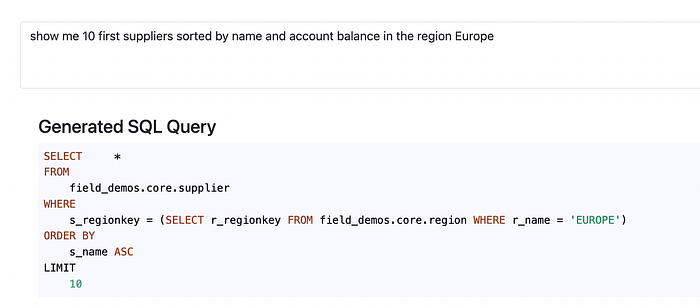
Okey, here we got it wrong — there is no direct link between region and supplier, it needs to be done via nationkey field first. Let’s try re-generating it a couple of times more (predictions made by this API are not determined, so every time you run a new generation you might get pretty various results:
After roughly 2–3 tries, we got a correct one — huge leap!
Now let’s try something more advanced, e.g. complex query with time and multiple joins.
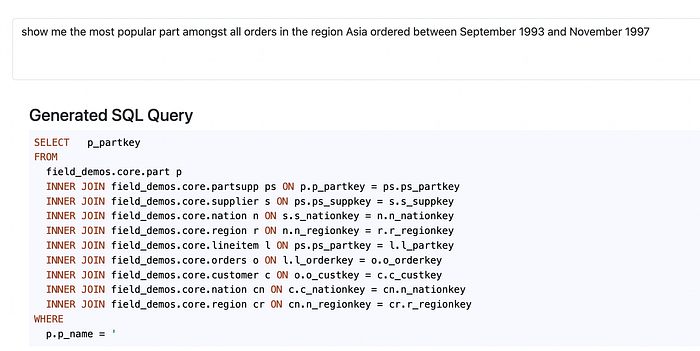
Seems like this time things got too complex, let’s try adding more max_tokens since it might be a pretty complex query.
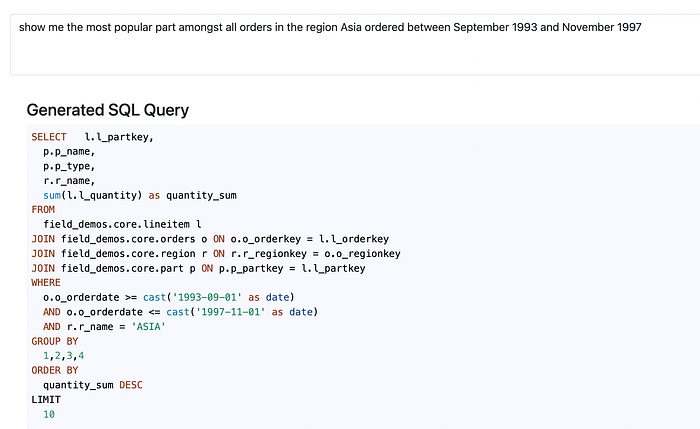
Well, this time we actually got much closer — at least the filters in the WHERE condition are correct, but once again it tries to make a join on a non-existent column.

After roughly 7 retries I got the answer which in my opinion satisfies the natural language query quite close. Although I was looking for only one popular part, and the predicted query selected the top-10, it’s still pretty mature results, even custom filters were properly resolved.
Summary
In the beginning of this small experiment I was pretty much skeptical about the ability of GPT-3 based OpenAI model to actually translate complex natural language queries into valid SQL statements — and I’m happy to figure out that I was completely wrong — this model is on fire 🔥!
I assume that some more interesting applications and further developments could be done in this direction:
- OpenAI API provides capabilities for fine-tuning. I haven’t had a chance to dive deeper into this, but assuming that there will be some kind of feedback loop on top of the generated statement looks like a great opportunity to vastly improve the model towards specific use-case and specific domain data model.
- I haven’t seen an opportunity to provide more custom metadata information (e.g. column/table comments, or generic input string information), but I also would assume that such models shall be capable of consuming free-text format documents (e.g. descriptions from Confluence or JIRA tickets) to extract more specific information on how columns shall be connected to each other.
- Is there a potential to generate not only the
SELECT, but also theINSERT/CREATE/DELETEstatements, or even chaining them? Here I’m imagining the bright future where Data Engineers could simply describe the processing pipeline in natural language and then slightly adjust the generated statements to use them in real-life data pipelines.
What other cool ideas could be applied with OpenAI and metadata information from the domain data model? I encourage the audience to share ideas it in the comments to this post.
