Releasing and using Python packages with Azure DevOps and Azure Databricks
While working with Python notebooks and projects in a long-term scope, Data and ML engineers come to the idea of using best software development practices in terms of storing and versioning code artifacts.
One such practice is to organize common, widely re-used code blocks into packages, and store these packages in a reliable system that provides versioning and authentication capabilities.
In the case of an OSS project in Python, the most obvious choice would be to store your released projects directly in the main Python Package Index (PyPI). However I doubt that you would like to keep your enterprise code in a public space, so we need to organize a private package index.
Whilst there are multiple alternatives on how to organize a private package index, I prefer ready-to-use cloud solutions for that. Fortunately, Azure DevOps includes functionality for storing packages, and it’s called Azure Artifacts.
If you’re looking for the source code of the examples used in this blog post, look here.
Architecture
Here I’ve briefly outlined the solution architecture and the main components:
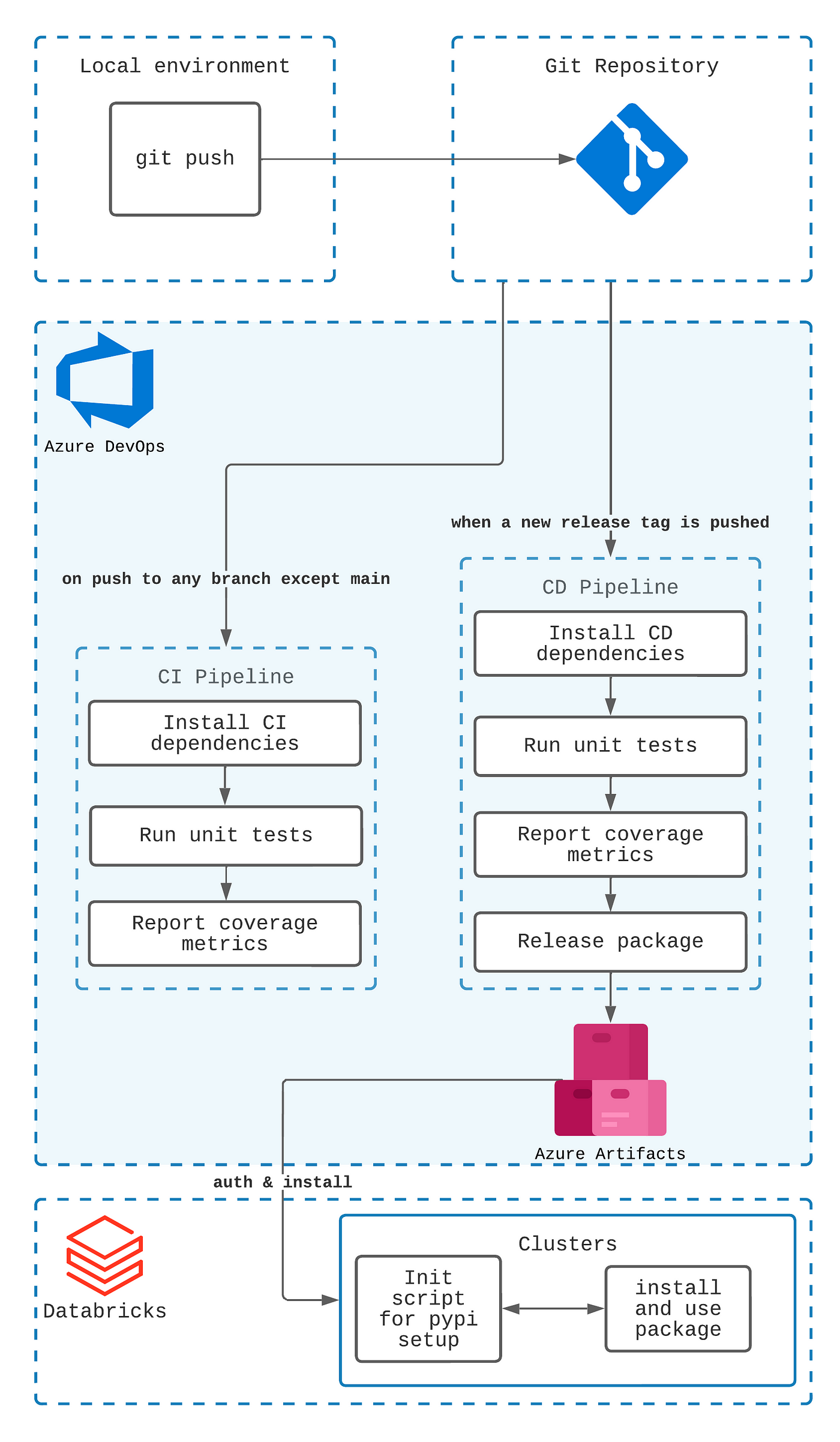
We start from the local repository, and on each push, we run a CI pipeline. When the time for a release comes, we trigger the release one, and it delivers the prepared package to Azure Artifacts.
On the Databricks side, we connect to the artifact repository (to properly pass auth variables we’ll set up an init script), and then we’re good to install and use our custom package in notebooks and jobs.
Writing the package
First, let’s assume that we’re writing a package that contains common Python functions which are used by many downstream teams in our organization. We’ll create a project based on standard Python structure:
.
|-- README.md
|-- azure-pipelines.yml
|-- databricks_python_packaging
| |-- __init__.py
| `-- utils
| |-- __init__.py
| `-- common.py
|-- notebooks
| `-- usage_example.py
|-- pytest.ini
|-- scripts
| `-- pip-config.sh
|-- setup.py
|-- tests
| `-- unit
| |-- conftest.py
| `-- vertical_append_test.py
`-- unit-requirements.txtQuick overview of the repo content:
azure-pipelines.ymlcontains our CI/CD pipeline definitionsdatabricks_python_packagingis a folder with the package source codesetup.pyis a python project file that describes the name, version, and other package properties.- all other files are relevant for testing and local dependency management
Assume we currently have one function in our package:
It’s a fairly simple function that vertically appends multiple data frames into a single data frame.
Following software development best practices, we indeed shall also add tests for this function:
I wouldn’t say it’s a good test — it only covers positive cases, but this time it’s not in the focus.
Now let’s create a new project in Azure DevOps and add the Git Source to it:

In the screen above I’ve created a project databricks-python-packaging and added the GitHub repository with the source code to it.
I also created a new feed in the Artifacts section, and made it project-scoped.

The next step is to define the CI/CD pipelines. I’ll only add the relevant parts here, please review the whole file in the linked repository if interested.
CI pipeline installs dependencies, runs tests, and collects coverage metrics:
And the release pipeline does the most relevant part — builds & uploads the distributed file to the Azure Artifacts feed I created earlier:
Now the classical steps for a release:
- bump version in
__init__.pyfile - commit & push code to the main branch
- create & push tag:
git tag -a "vX.Y.Z" -m "Release X.Y.Z"
git push origin vX.Y.ZAs a matter of fact, bumping versions could be automated with tools such as dunamai or Versioneer, but I’ll keep this automation bit away for the sake of focus.
After pushing the tag, the release pipeline will do its job and the released package will appear in the Azure Artifacts feed:

Installing package locally
Imagine now that the developers from one of the teams would like to use this package during the local testing scenario. In my case, it’s a Macbook with Apple M1, so I needed to install .NET SDK via installer and also install dependent packages:
pip install keyring artifacts-keyringIt’s also required to add an additional package index to the pip.conf file — follow these instructions.
When all pre-requisites are done, I can download and install the package via:
pip install databricks-python-packagingAnd use the function I’ve created in my own code.
Installing package in Azure Databricks
The final step is to install the package in the Azure Databricks environment. For that we’ll need to use the cluster node init scripts functionality, to configure the pip.conf file.
The simplest way to do it is the following:
- Create a new PAT token in Azure DevOps with permissions to read packages:

- Add the following secrets to the AKV in the same way:
- the above-generated token
- Azure DevOps feed name
- Azure DevOps organization name
- If your package is project-scoped (as in this example), add the project name as well.
Please note that this setup expects you to have an attached AKV to the Azure Databricks workspace. Find more on how to organize such a setup here.
Security note: for simplicity and demonstration sake I’m doing the steps above manually. In a full-scale enterprise setup these steps shall be peformed either via Azure ARM or Terraform provider (or any other IaaC solution). Don’t manage your tokens manually and always rotate them.
On the Databricks side of things, we’ll need to create a new init script which will populate the pip.conf file:
Now we can configure the interactive clusters to use this script and relevant secrets (don’t forget to add the uploaded script to the cluster init scripts configuration):

After this setup, any cluster with the attached init script and provided env variables will be able to install the provided package:
%pip install databricks-python-packagingLet’s use our newly packaged function for demonstration purposes:

Summary
Cloud platforms provide ready-to-use interfaces for software development best practices, although it requires a bit of infrastructure setup.
For the sake of focus, I’ve intentionally avoided going too deep into infra-level setup (although it’s not the hardest thing to automate). Another simplification step is to add a cluster policy that automatically propagates the env variables mapping to the cluster definitions.
